更新:2007-
對映章節:
本文翻译自源代码包中的“pgpool-II Tutorial”文档
定义数据分布规则
我们将定义把pgbench生成的示例数据分布在三个数据库节点的分布规则,在这个小节中创建名为“bench_parallel”的数据库,并且使用“pgbench -i -s 3”生成示例数据。
在pgpool-II源代码的sample目录能够找到dist_def_pgbench.sql文件,使用这个文件创建数据分布规则,执行如下命令:
$ psql -f sample/dist_def_pgbench.sql -p 5432 pgpool
以下是dist_def_pgbench.sql文件内容的解释。
插入四行数据到数据表“dist_def”中。每个数据表(前边提到过的accounts、branches、tellers以及history)各自有一个不同的分布函数。分别为branches、tellers、accounts 定义bid、tid、aid作为他们的key-columns字段(这几个字段也是他们的主键),history以tid作为key-columns字段。
INSERT INTO pgpool_catalog.dist_def VALUES (
'bench_parallel',
'public',
'branches',
'bid',
ARRAY['bid', 'bbalance', 'filler'],
ARRAY['integer', 'integer', 'character(88)'],
'pgpool_catalog.dist_def_branches'
);
INSERT INTO pgpool_catalog.dist_def VALUES (
'bench_parallel',
'public',
'tellers',
'tid',
ARRAY['tid', 'bid', 'tbalance', 'filler'],
ARRAY['integer', 'integer', 'integer', 'character(84)'],
'pgpool_catalog.dist_def_tellers'
);
INSERT INTO pgpool_catalog.dist_def VALUES (
'bench_parallel',
'public',
'accounts',
'aid',
ARRAY['aid', 'bid', 'abalance', 'filler'],
ARRAY['integer', 'integer', 'integer', 'character(84)'],
'pgpool_catalog.dist_def_accounts'
);
INSERT INTO pgpool_catalog.dist_def VALUES (
'bench_parallel',
'public',
'history',
'tid',
ARRAY['tid', 'bid', 'aid', 'delta', 'mtime', 'filler'],
ARRAY['integer', 'integer', 'integer', 'integer', 'timestamp without time zone', 'character(22)'],
'pgpool_catalog.dist_def_history'
);
接下来,必须为每个表定义分布函数,不同的表可以使用同一个分布函数,并且使用过程语言(PL/pgSQL、PL/Tcl等等)定义而不是SQL。
下边是由pgbench -i -s 3生成的数据概要:
| 数据表名 | 数据行数 |
| branches | 3 |
| tellers | 30 |
| accounts | 300000 |
| history | 0 |
继续定义4个函数将上述数据平分到三个节点,根据给出的参数返回0、1或者2
CREATE OR REPLACE FUNCTION pgpool_catalog.dist_def_branches(anyelement)
RETURNS integer AS $$
SELECT CASE WHEN $1 > 0 AND $1 <= 1 THEN 0 WHEN $1 > 1 AND $1 <= 2 THEN 1 ELSE 2 END; $$ LANGUAGE sql; CREATE OR REPLACE FUNCTION pgpool_catalog.dist_def_tellers(anyelement) RETURNS integer AS $$ SELECT CASE WHEN $1 > 0 AND $1 <= 10 THEN 0 WHEN $1 > 10 AND $1 <= 20 THEN 1 ELSE 2 END; $$ LANGUAGE sql; CREATE OR REPLACE FUNCTION pgpool_catalog.dist_def_accounts(anyelement) RETURNS integer AS $$ SELECT CASE WHEN $1 > 0 AND $1 <= 100000 THEN 0 WHEN $1 > 100000 AND $1 <= 200000 THEN 1 ELSE 2 END; $$ LANGUAGE sql; CREATE OR REPLACE FUNCTION pgpool_catalog.dist_def_history(anyelement) RETURNS integer AS $$ SELECT CASE WHEN $1 > 0 AND $1 <= 10 THEN 0 WHEN $1 > 10 AND $1 <= 20 THEN 1 ELSE 2 END; $$ LANGUAGE sql;检验并发查询重新启动pgpool-II载入pgpool.conf的变化,然后我们来检验一下并发查询是否在正常运行。
首先,命名为“bench_parallel”的分布数据库,通过pgpool-II创建到每一个节点上:
$ createdb -p 9999 bench_parallel接下来,生成测试数据:
$ pgbench -i -s 3 -p 9999 bench_parallel预想的数据分布情况:
| 数据表名 | Key-Column名 | 值 |
| 节点1 | 节点2 | 节点3 |
| branches | bid | 1 | 2 | 3 |
| tellers | tid | 1 - 10 | 11 - 20 | 21 - 30 |
| accounts | aid | 1 - 100000 | 100001 - 200000 | 200001 - 300000 |
| history | tid | 1 - 10 | 11 - 20 | 21 - 30 |
简单的验证脚本,比较每个节点的结果和pgpool-II的结果:
$ for port in 5432 5433 5434 9999; do
> echo $port
> psql -c "SELECT min(aid), max(aid) FROM accounts" -p $port bench_parallel
> done(accounts有30万数据,这个愚蠢的脚本不是我写的,除非你是超人,否则用这个脚本什么也不能做。)
今天不在状态,脑子很乱,可能是放假综合症发作。黄金周到来,暂时不再写什么东西,放松几天。后边可能(仅仅是可能)会写写关于pgbench方面的,毕竟前边的文章已经涉及到,了解一下也好。这几天的帖子都没有经过仔细校正,基本上写完就commit,难免有错别字语意不通之类。
这几天各种事情缠绕(真的是缠绕)着我,脑筋有点不够用,手头的project马上进入编码阶段,后边时间也许会很紧张没时间写东西。
延伸閱讀(Link):
pgpool官方英文网站pgpool-II官方英文网站
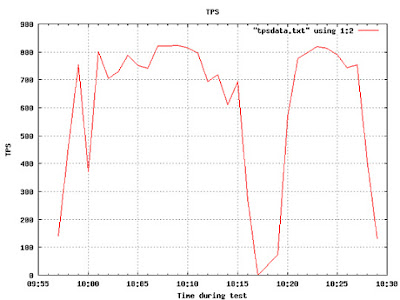 纵轴是TPS,横轴是时间,正如我们看到的,在10:17性能变得非常低下,这就是checkpoint的影响。
纵轴是TPS,横轴是时间,正如我们看到的,在10:17性能变得非常低下,这就是checkpoint的影响。 8.2.3之上的数据如下:
8.2.3之上的数据如下:
 与8.3相比,虽然8.2的整体性能比较低,但是没有像8.3那样极端的性能下降。这不能说明8.3有这样的性能偏差,实际上在不同硬件平台使用同样的方法取得数据,8.3出现波峰和波谷变化的现象也比较少。
与8.3相比,虽然8.2的整体性能比较低,但是没有像8.3那样极端的性能下降。这不能说明8.3有这样的性能偏差,实际上在不同硬件平台使用同样的方法取得数据,8.3出现波峰和波谷变化的现象也比较少。
 采用的机器是刀片服务器(Blade Server),其中一台运行pgpool-II和benchmark工具pgbench,其余9台运行PostgreSQL数据库。
采用的机器是刀片服务器(Blade Server),其中一台运行pgpool-II和benchmark工具pgbench,其余9台运行PostgreSQL数据库。
 纵轴是TPS,即每秒钟被执行的事务数,正如我们看到的,HOT有效的情况下性能大约提高一倍,也就是说HOT的效果是很大的。
纵轴是TPS,即每秒钟被执行的事务数,正如我们看到的,HOT有效的情况下性能大约提高一倍,也就是说HOT的效果是很大的。















